stupidb.functions.associative¶
Segment tree and corresponding aggregate function implementations.
The segment tree implementation is based on Leis, 2015
This segment tree implementation uses
AssociativeAggregate instances as
its nodes. The leaves of the tree are computed by calling the
step() method
once when the tree is initialized. The fanout of the tree is adjustable.
From the leaves, the traversal continues breadth-first and bottom-up during
which each interior node’s current aggregation state is combined with those of
its children by calling the
combine()
method. This method takes another instance of the same aggregation as input and
combines the calling instance’s aggregation state with the input instance’s
aggregation state.
Each interior node therefore contains the combined aggregation value of all of its children. This makes it possible to compute a range query in \(O\left(\log{N}\right)\) time rather than \(O\left(N\right)\).
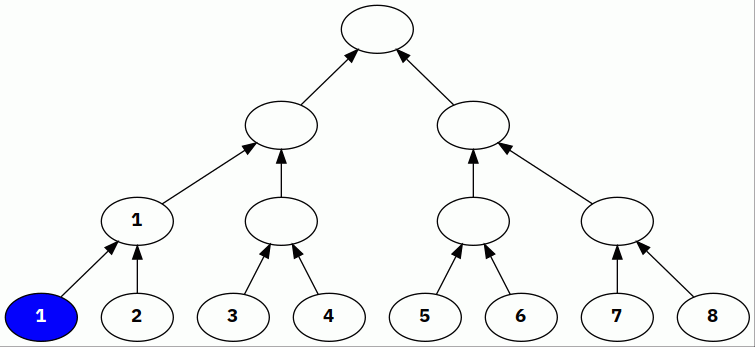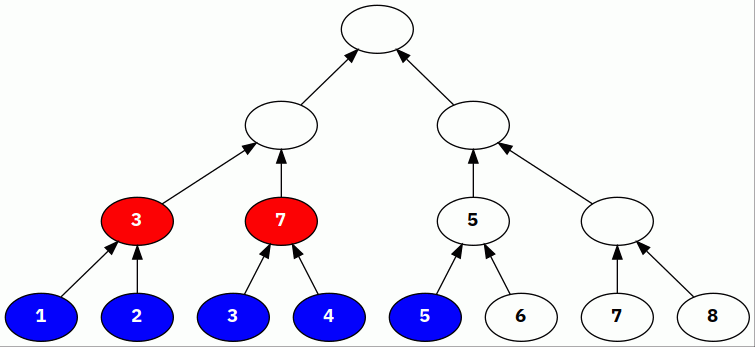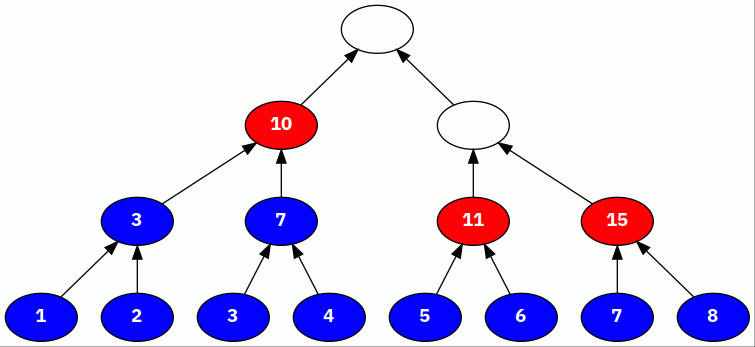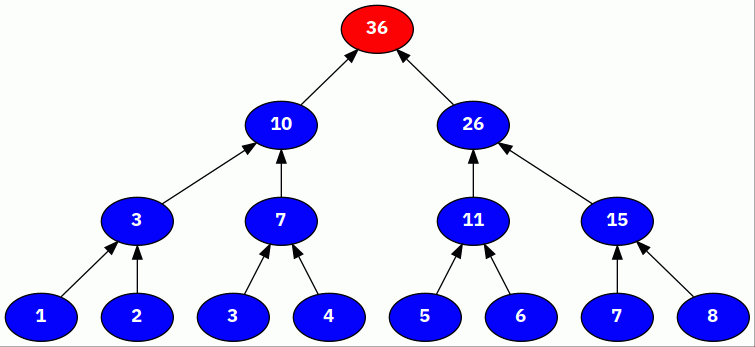
Here’s an example of a segment tree for the
Sum aggregation, constructed with the
following leaves and a fanout of 2:
[1, 2, 3, 4, 5, 6, 7, 8]
Blue indicates that a node was just aggregated into its parent, and red indicates a node that contains the aggregate value of all of its children.
Note
You can generate this GIF yourself by typing:
$ python -m stupidb.associative.animate > segment_tree.gif
at the command line, after you’ve installed stupidb. The code used to
generate the GIF lives in stupidb.associative.animate.
Using segment trees in this way results in window aggregations having \(O\left(N\log{N}\right)\) worst case behavior rather than \(O\left(N^{2}\right)\), which is the complexity of naive window aggregation implementations.
A previous iteration of stupidb had \(O\left(N\right)\)
worst case behavior for some aggregations such as those based on sum. The
segment tree implementation provides a generic solution for any associative
aggregate, including min and max as well as the typical sum based
aggregations, that gives a worst case runtime complexity of
\(O\left(N\log{N}\right)\).
A future iteration might determine the aggregation algorithm based on the specific aggregate to achieve optimal behavior from all aggregates.
Classes
|
Count column values. |
|
Base class modeling the covariance of two columns. |
|
Maximum of column values. |
|
Average values in a column. |
|
Minimum of column values. |
|
Base class modeling min/max order statistics. |
Population covariance of two columns. |
|
Population standard deviation of a column. |
|
Population variance of a column. |
|
Sample covariance of two columns. |
|
Sample standard deviation of a column. |
|
Sample variance of a column. |
|
|
Base class modeling the standard deviation of a column. |
|
Sum column values, ignoring nulls. |
|
Sum column values, preserving nulls. |
|
Base class modeling the variance of a column. |
- class stupidb.functions.associative.Covariance(*, ddof)[source]¶
Base class modeling the covariance of two columns.
- class stupidb.functions.associative.MinMax(*, comparator)[source]¶
Base class modeling min/max order statistics.
- class stupidb.functions.associative.PopulationCovariance[source]¶
Population covariance of two columns.
- class stupidb.functions.associative.PopulationStandardDeviation[source]¶
Population standard deviation of a column.
- class stupidb.functions.associative.SampleStandardDeviation[source]¶
Sample standard deviation of a column.
- class stupidb.functions.associative.StandardDeviation(ddof)[source]¶
Base class modeling the standard deviation of a column.
- class stupidb.functions.associative.Variance(ddof)[source]¶
Base class modeling the variance of a column.
Modules